Introduction
Containers have revolutionized modern programming, enabling microservice architecture like never before. Not familiar with containers? Think of them as packages containing the bare minimum resources necessary to run an application. These resources include code, dependencies, libraries, system settings, and more. Containers also natively run on Linux, sharing the host machine’s kernel with other containers, making them much lighter than virtual machines. As a result, many developers choose to deploy their applications/microservices within containers, a process known as containerization.
However, with containerization comes new problems. If you have a large project, you might wonder how on earth you’re going to manage all these containers? Ideally you’ll have a CI pipeline for building, testing, and verifying the container images before you run them on whatever infrastructure you have. Not only that, controllers don’t launch themselves, and once they’re running they can fail. What if you also have too many or not enough at one time? At this point, we’re in dire need of a better system for our containers. This is where Kubernetes comes in.
Kubernetes is what is known as a container orchestrator, meaning it groups systems together to form clusters for container deployment and management to be automated at scale. Besides making your containers usage optimal, it also helps with fault tolerance, self healing, on-demand scaling, and seamless updates/rollbacks without downtime. But don’t just take my word for it, it’s even better straight from the source! Did I mention the Kubernetes docs are great?
Here are some other Kubernetes tidbits: The name Kubernetes comes from a greek word κνβερνητης meaning helmsman, or ship pilot. You may also see Kubernetes abbreviated to k8s (pronounced Kate’s), this is because developers are lazy and just counted the letters in between the starting and ending characters and slapped that number in there. One more bonus fact is that Kubernetes was started by Google, and was heavily influenced by a project called Borg.
You might ask why I’m writing this. I recently took an introductory course on Kubernetes from edX, as it was recommended by the CNCF training page. It is a very informative course that breaks down a lot of the theory behind how Kubernetes functions, and I’ll do what I can to condense it into more digestible content. However, there really is no substitute for the real thing, so if you’re interested in a deep dive feel free to check it out. It’s also free, although they bug you to pay $99 to verify that you’re learning the information.
How does it work?
At a high level, Kubernetes is fairly simple to visualize. Here’s an example from the edX course I mentioned earlier:
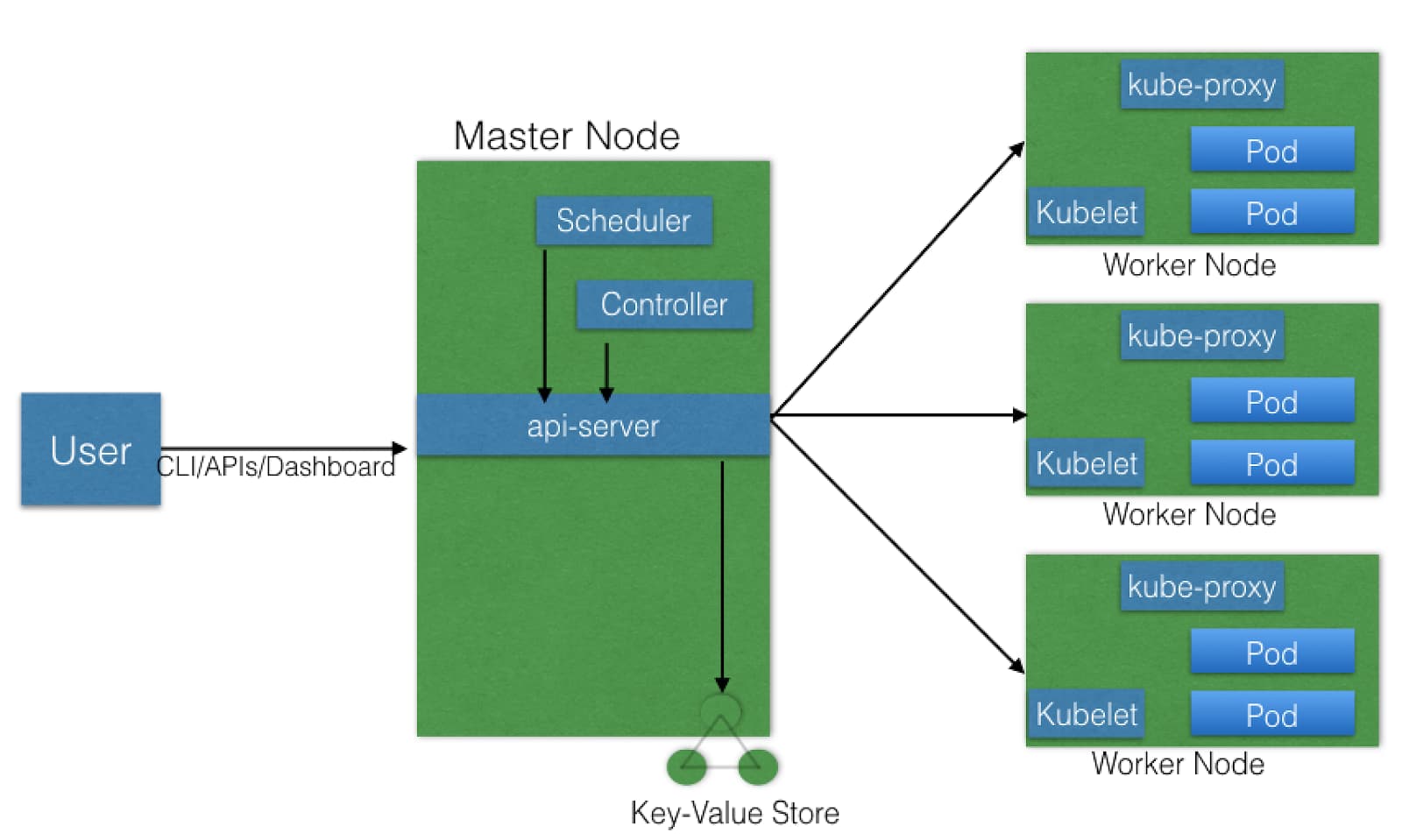
Master Node
Your users, aka CLI’s, APIs, or even a dashboard, communicate with the Kubernetes master node. By the way, Kubernetes Nodes are just physical or virtual machines, so you’ll need to get your infrastructure set up before you can run Kubernetes. There is an excellent walkthrough called Kubernetes the Hard Way by Kelsey Hightower that (somewhat painfully) makes sure you’re familiar with all the necessary parts to run Kubernetes. The master node can be replicated for redundancy, and you may also choose to have a load balancer fronting these nodes as well. As the diagram indicates, there are a few core components to the master node, so let's get into those!
etcd
One thing you should know is that Kubernetes constantly tries to match a desired cluster state. This state information is distributed in the etcd key-value store on the master node, which is then synced across other replications if there are any. Container settings and network configuration are also stored in etcd, but not application related data or settings. Bonus fact, if you were wondering what etcd stands for, the etc part refers to the /etc folder where configurations are typically stored, and the d is for distributed.
kube-apiserver
This is the part most things interact with, as it is the main hub for internal and external communication. RESTful calls from users, operators, and external agents are validated and processed here. The current cluster state gets read from etcd and, after the call’s execution, the resulting state is saved in etcd for persistence. Of all the master plan components, only the API server can speak with etcd. The command line client for Kubernetes, kubectl, is designed to communicate with the API server and comes built in with lots of help, so don’t worry if you think there are too many options, the answers are all in there somewhere! Also a little note, kubetcl is largely a fancy wrapper for curl, so if you’re comfortable making custom curl commands go right ahead!
kube-scheduler
The scheduler is tasked with assigning new objects like Pods to nodes. If you’re like me and have no clue what a Pod is, don’t worry, it’s pretty much just a collection of one or more containers. It also happens to be the smallest schedulable unit in Kubernetes. The scheduler figures out which nodes to use based on the current Kubernetes cluster state, which it gets from the API server, and said object’s requirements. These requirements may include user or operator set constraints, such as ensuring the object is scheduled on a node labeled with a disk==ssd key/value pair. Keep in mind that the scheduler becomes more important and complex in a multi-node kubernetes cluster.
kube-controller-manager
This controller manager is responsible for acting when nodes become unavailable, ensuring Pod counts are as expected, creating endpoints, service accounts, and API access tokens. There’s a lot going on for this controller manager, so it always has to be on the lookout for state changes. The cloud-controller-manager is a recent addition that regulates interaction with cloud providers in regards to storage volumes, load balancing, and routing. It’s not in the figure above, but it’s still good to know it exists, since most of the time Kubernetes does use cloud service integration.
More to come
Even though I've condensed the information, there's still a lot to take in! Rather than numb your mind with new terminology and concepts, I'll continue this post next week with part two, where I'll cover worker nodes and data storage. I'll also have some new resources to check out that are more hands on and pretty quick to set up, so stay tuned!



